Is MIME Sniffing XSS a real thing? [The story of weird Google bug bounties]
- Komodo Research
- May 15, 2019
- 5 min read
Updated: Sep 23, 2025

Let’s start at the end. This one got me seriously confused. It all started a few months ago when a colleague was hacking away at some Google website. After some poking around, he detected a persistent XSS vulnerability – the attacker’s payload is stored on the server side and returned to the user without encoding. There was only one catch – The Content-Type of the server response was set to ‘multipart/form-data’ meaning that the browser will not evaluate the HTML and will not execute the JavaScript.
- “I Think I’ll report it,” my colleague said, “Maybe it can be exploited with mime-sniffing.”
- “Good luck,” I responded, with a mocking tone. “You know as well as I that mime-sniffing is dead”.
- “we’ll see”, he said “I have nothing to loss by reporting”
Soon after my Colleague was rewarded by Google with few thousand dollars for this issue. Within few days he detected yet another instance of mime-sniffing-dependent-XSS, and was rewarded with few thousand dollars more.
- “What the hell?” I asked him.
- “I’m not sure myself”, he replied, “But if they pay me the bounties I’m not arguing. Besides, maybe they know something we don’t.”
This raised a question in my mind: what is mime sniffing and how do mime sniffing vulnerabilities play a role in XSS exploits?
OK, I thought, homework time!
MIME sniffing in a nut shell
Generally speaking, browsers look at the Content-Type header in the HTTP response for an indication of how the response should be interpreted. Typically, if the application wants the browser to render HTML content, the HTTP response should include the ‘text/html’ content-type. Similarly, ‘image/jpeg’ content-type should be used for images, etc.
‘Typically’ is the crucial word in that sentence, as different browsers tend to have different approaches for evaluating content-types especially when unknown content-types are used (‘unknown’ in the sense that the specific browser does not have clear instructions on how to evaluate it). In such a case, the browser may try to perform mime-sniffing, i.e. try to ‘understand’ from the content itself how it should be interpreted.
Such mime sniffing vulnerabilities can allow attackers to execute unexpected code or scripts, making it an important consideration even in modern browsers.
In the context of XSS, if the content ‘resembles’ HTML, the browser might understand it as HTML even if the content-type is not set to ‘text/html’. Understanding what is mime type sniffing is key to grasping why certain XSS issues only trigger under specific conditions, especially with content types like ‘multipart/form-data’ or unknown MIME types.
Confused? You’re not alone.
When exactly will the browser attempt such a ‘self-understanding’ approach? It depends on the browser, of course, but generally it’s quite a rare thing and mostly applicable to old browsers (How old? IE 4 old). To make the attack even less plausible, a specific header (‘X-Content-Type-Options: nosniff’) can be set by the server to indicate to the browser that it should not perform mime-sniffing. This capability has been supported by most major browsers (with the exception of Safari) for quite some time (even in IE 8).
Missing ‘XCTO header’? Nope
Back to the XSS in Google. My colleague considered his mime-sniffing XSS to be a ‘slightly more real’ XSS (i.e. has chances to be exploited in the real world), as the server response he received lacked the ‘X-Content-Type-Options: nosniff’ header, which means that the browser might perform MIME-Sniffing in some cases.
Without proper headers, mime confusion attacks exploit the browser’s attempt at mime type sniffing, demonstrating that even minor oversights can create exploitable mime sniffing vulnerabilities.
While I was not entirely convinced (neither of us were able to create a POC that actually works), I could sort-of accept that Google holds itself to the highest security posture, thus accepting the lack of header as an issue. That is until I found my own XSS.
The most confusing Google response of all time
A few weeks later, I found my own instance of persistent XSS with non-HTML content type. In my case, the ‘X-Content-Type-Options: nosniff’ was set. Nonetheless, not wanting to miss out on all this bounty goodness, I submitted it as a bug. This triggered the most confusing Google response I could think of.
Originally, the bug was rejected, as I could not provide a POC. This was the result I expected. Later, though, this happened:
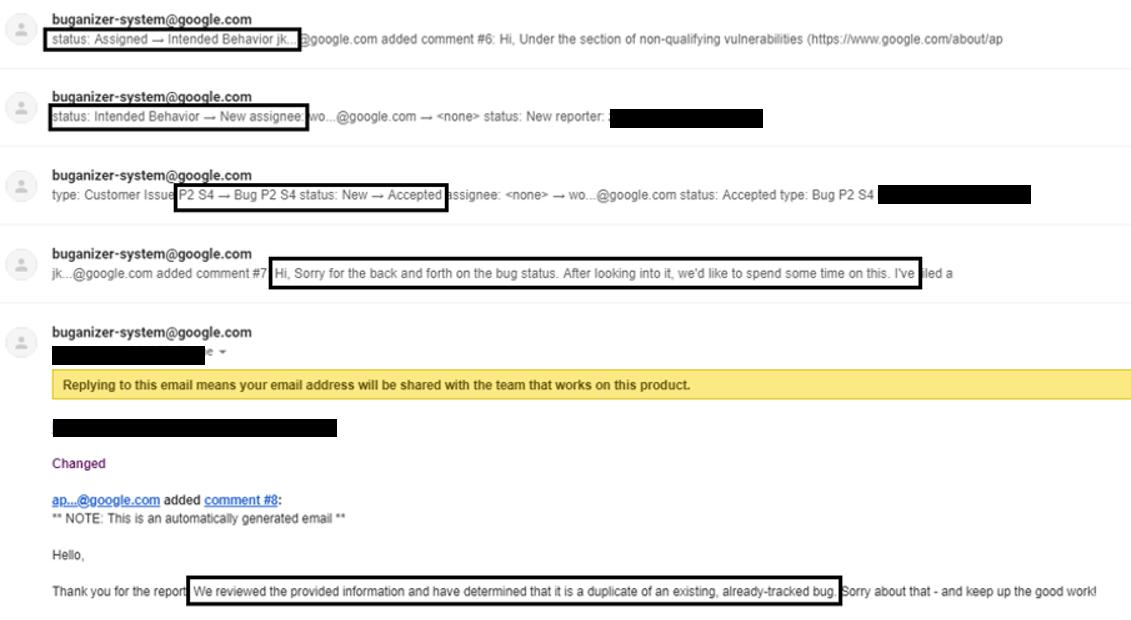
Without any new data from me, Google switched from ‘intended behavior,’ to ‘new,’ to ‘accepted’ just to realize a week later that they were already following this as a bug.
Apparently, I’m not the only one to be confused about mime-sniffing. I decided to tackle the issue once and for all and asked Google about it. That was very helpful:
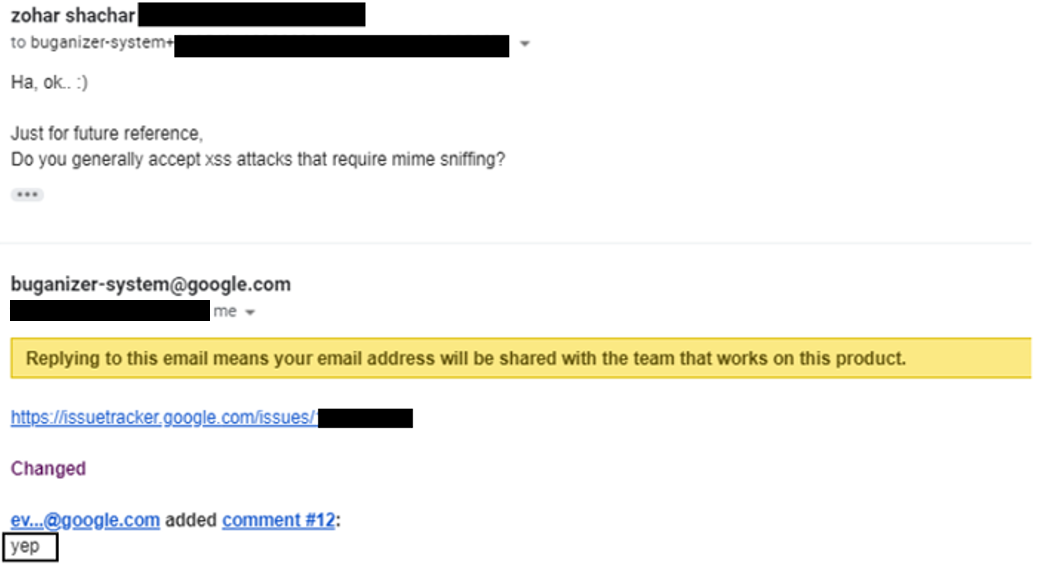
Problem solved indeed.
At this point I felt that more data is needed (and let’s be honest, more bounties too). So, I decided to invest some time in detecting more such instances and in reporting everything I find.
Bounties, bounties, bounties
In the following months I’ve detected and reported several more instances, each with slightly different characteristics, including a ‘ZIP’ document response (content-disposition set to ‘attachment’), ‘plain/text’ content type, ‘CSV’ content type, and even ‘Custom’ content-type. Without fail, all of the bugs I’ve reported were accepted (expect those deemed as duplicates), though several required some ‘convincing’:

Ah ha! ‘Weird stuff!’ That explains everything. I can now use Google tricks against them:

After that last email, the bug was accepted (and I was rewarded).
Final thoughts
Personally, my thoughts after this research remained similar to those I had before – while I accept that it is a theoretical risk, an XSS that requires mime-sniffing just doesn’t cut it for me. And I’m not alone – as shown above, at least some Google security engineers don’t really see the risk either.
With that being said, studying what is mime sniffing, mime sniffing vulnerabilities, and mime confusion attacks provides valuable insights into securing applications against subtle XSS threats.
With that being said, I have huge respect for Google here for making the decision to treat such XSS as a real risk. Their decision to put their users’ security as first priority and fighting such esoteric vulnerabilities (even at the cost of paying good bounty money) can only be appreciated and I wish other organizations of such caliber would take security half as seriously as Google does.
Founded by leading consulting experts with decades of experience, the KomodoSec team includes seasoned security specialists with worldwide information security experience and military intelligence experts. We deliver regulator-grade, intelligence-led red team tests on live production that cover critical or important functions, include key third parties, follow the EU TLPT RTS and TIBER-EU guidance end-to-end, and produce the exact artifacts supervisors expect for validation and attestation.



Really enjoyed this story—MIME sniffing being “dead” but still showing up in the wild is a great reminder that browser behavior, headers, and content-type handling can be subtle and security-relevant. The step-by-step bounties arc also makes the reporting and verification process feel tangible. CSV to JSONLines
This was a fascinating read! I’ve always been intrigued by how small browser behaviors can lead to serious vulnerabilities. The example of MIME sniffing leading to XSS really highlights how complex and unpredictable web security can be. It’s easy to underestimate these edge cases until they’re exploited. I had no idea Google awarded bug bounties for things like this. It makes me want to dig deeper into similar case studies. I’d love to know more about other overlooked threats that have caused major issues. Thanks for shedding light on this topic in such an engaging and detailed way!